
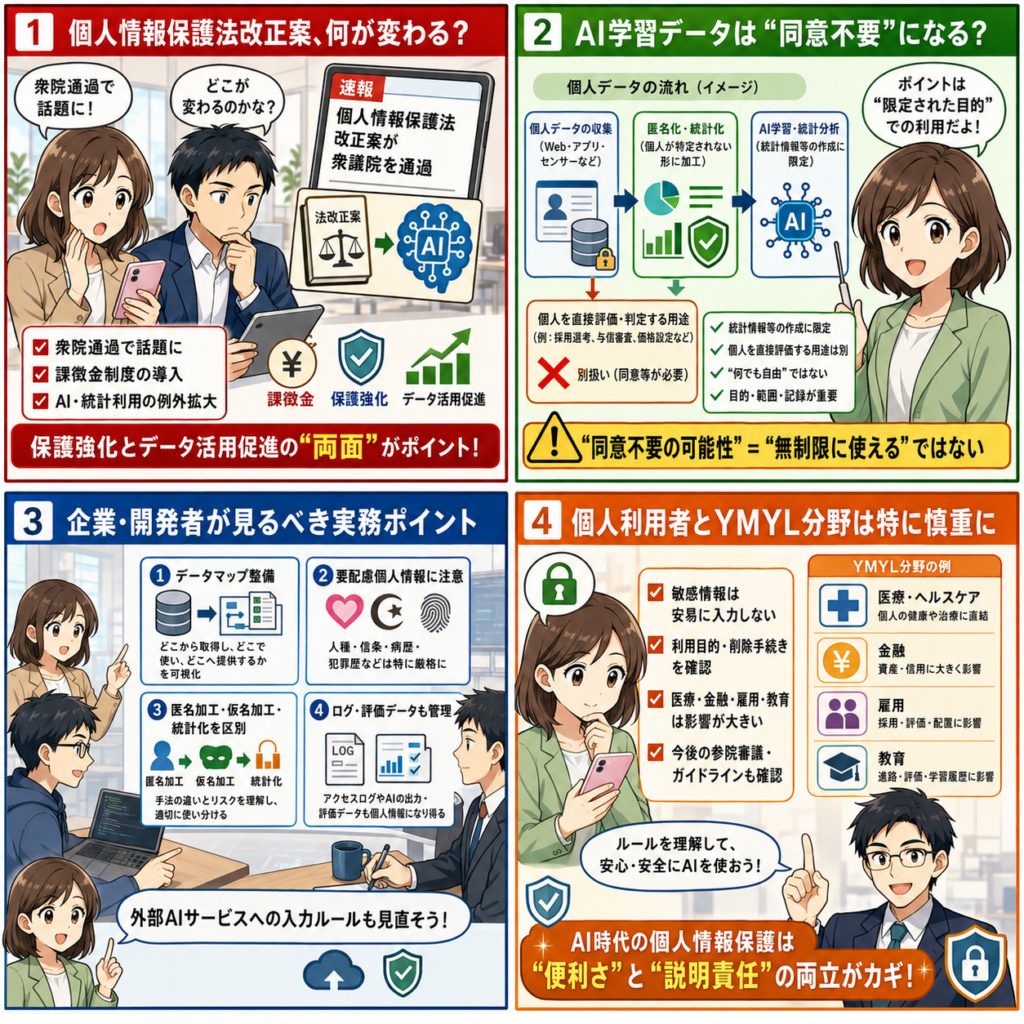
2026年5月27日のXでは「個人情報保護法改正案」「悪質業者」「個人情報とAI学習」といった言葉が話題になりました。背景には、個人情報保護法改正案が2026年5月26日に衆院本会議を通過したという報道があります。今回の改正案では、悪質な個人情報の取り扱いに対する課徴金制度の導入と、AI開発や統計作成などに関わるデータ利用の例外拡大が大きな論点になっています。
この記事では、企業担当者、開発者、個人利用者が理解しておきたいポイントを、できるだけ実務に近い形で整理します。法律の個別適用は事実関係、業種、データの種類、利用目的、委託・共同利用・第三者提供の形によって変わります。この記事は一般的な情報整理であり、法的助言ではありません。実際の対応は、個人情報保護委員会の資料、法令、ガイドライン、社内規程、弁護士などの専門家に確認してください。
改正案の中心にある二つの方向性
今回の改正案は、保護の強化とデータ利活用の促進という二つの方向性を同時に扱っています。一つ目は、悪質な事業者への課徴金制度です。個人情報を不正に取得したり、不適切に利用して利益を得たりする事業者に対して、金銭的な制裁を設ける考え方です。個人情報漏えいが社会的な信用低下だけでなく、経済的なリスクにも直結することになります。
二つ目は、AI開発や統計作成など、個人が特定されない用途に限ったデータ利用の例外拡大です。報道や個人情報保護委員会の資料では、統計情報等の作成にのみ利用されることが担保される場合、本人同意なしで個人データ等の第三者提供が認められる場面を広げる方向が示されています。AI開発をめぐる国際競争が激しくなるなか、日本国内でデータを活用しやすくする狙いがあります。
この二つは一見すると逆方向に見えます。片方では規制を強め、もう片方では利用を緩めるからです。しかし実務上は、どちらも同じ問題につながっています。つまり、データを使うなら目的、範囲、管理、説明、記録を明確にし、不正利用や本人への不利益を防がなければならないということです。単に「AI学習なら同意不要になる」と理解すると危険です。
AI学習データの同意例外は何を意味するのか
AI開発では、大量のデータが必要になります。文章、画像、音声、行動履歴、購買履歴、問い合わせ履歴、医療・教育・金融に関わるデータなど、さまざまな情報がモデルの学習や評価に使われます。現行制度では、個人データの第三者提供には原則として本人同意が必要です。要配慮個人情報や機微な情報を扱う場合は、さらに慎重な取り扱いが求められます。
改正案が注目されるのは、統計情報等の作成にのみ利用されることなどを条件に、本人同意がなくてもデータを提供・利用できる場面を広げようとしている点です。ここでいうポイントは「個人を特定して評価するためではなく、統計的な分析やAI開発のために使う」という条件です。個人への直接的な働きかけ、差別的なプロファイリング、本人に不利益を与える判断に使うことまで自由になるわけではありません。
企業が注意すべきなのは、AI学習という言葉が広すぎることです。モデルの事前学習、追加学習、評価データ、検索拡張、ログ分析、品質改善、広告配信、与信判断、採用選考、医療判断支援など、実際の利用場面は大きく異なります。統計情報等の作成にのみ使うのか、個人へのサービス提供に使うのか、第三者に渡すのか、委託先に処理させるのかで、必要な整理は変わります。

「同意が不要になる可能性がある」ことと「何をしてもよい」ことはまったく違います。利用目的を特定し、不要な項目を削り、識別性を下げ、アクセス権限を管理し、利用後の削除や保存期間を決め、第三者提供の記録を残す必要があります。AIの出力が個人に影響する場合は、入力データだけでなく、出力の使い方も確認しなければなりません。
要配慮個人情報と公開情報の扱い
個人情報保護法では、人種、信条、社会的身分、病歴、犯罪の経歴、犯罪被害に関する事実など、本人に対する不当な差別や偏見につながりうる情報を要配慮個人情報として扱います。これらは通常の個人情報より慎重な取り扱いが必要です。AI学習や統計目的の例外が広がるとしても、要配慮個人情報を含むデータについては、本人への影響や差別リスクを強く意識する必要があります。
特に注意したいのは、公開されている情報だから自由に使える、という誤解です。インターネット上で見られる情報でも、個人情報に該当する場合があります。SNS投稿、ブログ、掲示板、レビュー、画像、動画、音声、プロフィール情報などは、組み合わせによって個人を識別できることがあります。公開情報をAI学習に使う場合でも、収集方法、利用目的、本人への不利益、削除要請への対応、著作権や肖像権との関係を検討する必要があります。
また、病歴や犯罪歴などの情報は、本人に深刻な不利益を与える可能性があります。統計作成やAI開発に使う場合でも、個人が特定されないようにするだけでなく、特定の属性集団に不利な結果を生まないか、偏りを増幅しないかを確認することが重要です。AIモデルは学習データの偏りを反映するため、個人情報保護とAI倫理は切り離せません。
課徴金制度が企業に与える影響
課徴金制度は、個人情報の不適切な取り扱いを「信用問題」だけでなく「金銭的リスク」として可視化します。これまで情報漏えいや不正利用が起きた場合、行政指導、命令、刑事罰、損害賠償、ブランド毀損、取引停止などが主なリスクとして考えられてきました。課徴金が導入されると、不正に得た利益の相当額を納付させる仕組みが加わり、経営層にとっても無視しにくいリスクになります。
企業実務では、個人情報管理を情報システム部門や法務部門だけに任せるのではなく、事業部門、マーケティング、開発、データ分析、外部委託管理、経営層が同じ前提を共有する必要があります。AI活用を急ぐ現場では、データがあれば試したい、外部ツールへ投入したい、過去ログを分析したいという要望が出やすくなります。しかし、利用目的の範囲を超えていないか、本人同意や通知の前提とずれていないか、委託先との契約に問題がないかを確認しないまま進めると、後から大きな問題になります。
課徴金制度が入ると、違反が発覚した後の説明も厳しく見られます。誰が承認したのか、どのデータを使ったのか、どの目的で使ったのか、どの委託先に渡したのか、アクセスログは残っているのか、削除や停止ができるのか。こうした記録がなければ、違反の範囲を特定できず、被害拡大を防ぐ対応も遅れます。
企業がまず整理すべきデータマップ
改正案への対応で最初に取り組みたいのは、データマップの整備です。どの部署が、どの個人情報を、どの目的で、どこに保存し、誰がアクセスし、どの外部サービスや委託先に渡しているのかを一覧化します。AI活用を始める前に、そもそも社内にどんなデータがあるのかを把握していなければ、適切な判断はできません。
データマップでは、氏名、住所、メールアドレス、電話番号、会員ID、Cookie、端末ID、購買履歴、問い合わせ履歴、位置情報、画像、音声、健康情報、金融情報、子どもに関する情報などを分類します。次に、利用目的と保存期間を確認します。利用目的が古いままになっていないか、当初予定していなかったAI分析に使おうとしていないか、不要なデータを保存し続けていないかを見ます。
外部AIサービスを使う場合は、入力データが学習に利用されるのか、保存されるのか、国外に移転されるのか、管理者が削除できるのか、ログが残るのかを確認します。社内の生成AI利用ルールで「個人情報を入力しない」と定めていても、現場で問い合わせ文、契約書、顧客リスト、議事録をそのまま入れてしまうことがあります。ルールは作るだけでなく、使いやすい代替手段と教育が必要です。
匿名加工、仮名加工、統計化の違い
AIやデータ分析の現場では、匿名加工、仮名加工、統計化という言葉が混同されがちです。匿名加工情報は、特定の個人を識別できず、元の個人情報を復元できないように加工した情報です。仮名加工情報は、他の情報と照合しない限り個人を識別できないように加工した情報で、内部分析などに使いやすい一方、扱い方にはルールがあります。統計情報は、個人ではなく集団の傾向を示す形に集計した情報です。
AI学習では、完全に匿名化したつもりでも、他のデータと組み合わせることで再識別できる場合があります。特に希少疾患、特定地域、少人数の属性、独自の行動パターンを含むデータは注意が必要です。テキストデータでは、本文中に氏名、住所、会社名、学校名、病名、事件名などが残ることがあります。画像や音声では、顔、声、背景、制服、位置情報などから個人が推測されることがあります。
そのため、単に名前を消すだけでは十分とは限りません。データ最小化、マスキング、サンプリング、集計、ノイズ付与、アクセス制御、再識別テスト、利用者教育を組み合わせます。AIモデルに学習させた後も、モデルが個人情報を記憶して出力しないか、プロンプトによって抽出されないかを検証する必要があります。
社内規程に入れたい実務チェック
企業が改正案を見据えて社内規程を整えるなら、まずAIデータ利用の承認フローを明確にします。新しいデータセットをAI学習や分析に使うとき、誰が利用目的を確認し、誰が個人情報該当性を判断し、誰が委託先や第三者提供を承認するのかを決めます。小さな実験でも、顧客データや従業員データを使うなら記録を残します。
次に、禁止事項を明確にします。本人への重大な影響がある判断に使うデータ、要配慮個人情報を含むデータ、未成年者に関するデータ、秘密保持義務のある取引先情報、契約上外部送信が禁止されている情報などは、通常より厳しい承認を求めるべきです。外部生成AIサービスへの入力は、サービスの利用規約、学習利用の有無、保存期間、国外移転、管理者機能を確認してから許可します。
さらに、説明と問い合わせ対応も必要です。ユーザーから「自分のデータはAI学習に使われるのか」「削除できるのか」「第三者へ渡されるのか」と聞かれたとき、窓口が答えられなければ信頼を失います。プライバシーポリシーは長い文章を置くだけでなく、重要な利用目的をわかりやすく示し、変更時には適切に周知することが大切です。
開発者が気をつけたいログと評価データ
AI開発では、学習データだけでなくログと評価データも重要です。ユーザーの入力、AIの出力、フィードバック、エラー、問い合わせ、音声文字起こし、画像解析結果などは、サービス改善に役立ちます。しかし、これらには個人情報や機密情報が含まれる可能性があります。ログは「ついでに保存されるもの」と考えられがちですが、保存期間、閲覧権限、分析目的を決めておかなければリスクになります。
評価データにも注意が必要です。モデルの性能を測るために、実際の問い合わせや顧客文書を抜き出して使う場合、個人名や具体的な事情が含まれていることがあります。評価用データは開発者や外部ベンダーが見ることもあるため、マスキングやサンプル化が必要です。品質改善のために人手レビューを行う場合も、レビュー担当者の権限、秘密保持、閲覧ログを管理します。
また、AI出力の監視も重要です。モデルが学習データに含まれる個人情報をそのまま出力しないか、特定人物への評価や差別的な推測をしないか、医療・金融・法律など高リスク領域で過度に断定しないかを確認します。個人情報保護は入力データだけの問題ではなく、出力が本人にどう影響するかまで含みます。
個人利用者が知っておきたいこと
個人利用者にとって今回の改正案は、少し距離のある話に見えるかもしれません。しかし、AIサービスやデータ活用が広がるほど、自分の情報がどのように使われるかを確認する力が重要になります。サービス登録時には、利用目的、第三者提供、外部送信、AI学習利用、削除手続き、問い合わせ窓口を確認しましょう。すべてを細かく読むのは現実的に難しくても、医療、金融、子ども、位置情報、顔写真、音声など敏感な情報を扱うサービスでは特に注意が必要です。
生成AIを使うときも、自分や他人の個人情報を安易に入力しないことが大切です。履歴書、診断書、契約書、学校の書類、顧客リスト、家族の事情、事件やトラブルの詳細などは、便利だからといってそのまま投入しないほうが安全です。要約や相談に使う場合は、個人名や具体的な住所、連絡先、識別できる情報を削る、社内ルールを確認する、必要なら専門家に相談するなどの対応が必要です。
SNS上では、改正案について「企業が同意なしに何でもできるようになる」といった強い表現も出やすくなります。懸念を持つことは重要ですが、制度の条件や対象を確認せずに判断すると、必要以上に不安が広がることもあります。法律案の審議、個人情報保護委員会の資料、信頼できる解説を見ながら、何が変わり、何が変わらないのかを分けて理解しましょう。
YMYL領域で特に慎重に見るべき分野
医療、金融、雇用、教育、行政、子どもに関するデータは、本人の生活に大きな影響を与えます。AI学習や統計利用の例外が広がるとしても、こうした領域では、データの利用目的、説明、同意、異議申立て、削除、監査、差別防止を慎重に設計する必要があります。たとえば医療データを統計研究に使うことは社会的価値がありますが、個人が特定されたり、保険や雇用で不利益に使われたりすれば重大な問題になります。
金融領域では、取引履歴、収入、資産、借入、支払い遅延、投資行動などが含まれます。AIによる与信、投資助言、保険料算定、広告配信では、本人に直接影響が及びます。雇用領域では、採用、評価、配置、退職リスク分析などにAIを使う場合、説明責任や公平性が問題になります。教育では、学習履歴や子どもの行動データが長期間残る可能性があります。
これらの分野では、法令遵守だけでなく、社会的な納得性が重要です。規約上は可能でも、利用者が「そんな使われ方は想定していなかった」と感じれば信頼を失います。AI活用を進める企業ほど、利用者に説明できる設計を先に作るべきです。
参院審議と今後の確認ポイント
改正案は衆院を通過した段階であり、今後の審議や委員会規則、ガイドライン、実務解釈によって細部が見えてきます。企業担当者は、法律案の条文だけでなく、施行時期、経過措置、個人情報保護委員会の規則、Q&A、ガイドライン改正を追う必要があります。特に、統計情報等の作成にのみ利用されることをどう担保するのか、本人への通知や公表はどの程度必要か、第三者提供記録はどう扱うのか、要配慮個人情報の範囲はどう整理されるのかが重要です。
また、AI関連法制や著作権、消費者保護、独占禁止法、サイバーセキュリティ、労働法との関係も見逃せません。個人情報保護法だけを満たしていても、他の法律や契約に違反する可能性があります。たとえば、顧客データを外部AIサービスへ入力する場合、個人情報保護法、秘密保持契約、委託契約、国外移転、セキュリティ基準、業界規制が重なります。
今すぐできる準備は、改正案の細部を待つことだけではありません。データマップの整備、AI利用ルールの見直し、外部サービスの棚卸し、ログ管理、従業員教育、問い合わせ対応、委託先管理、リスク評価の仕組みづくりは、どのような最終形になっても役立ちます。
まとめ
個人情報保護法改正案の衆院通過は、AI時代のデータ利用を考えるうえで重要な節目です。改正案は、悪質な事業者への課徴金制度によって保護を強める一方、AI開発や統計作成に関わるデータ利用の例外を広げようとしています。これは、データを使いやすくする話であると同時に、目的、管理、記録、説明の責任を重くする話でもあります。
企業は「同意不要」という言葉だけを切り取らず、どのデータを、何の目的で、どの範囲で、誰に渡し、どのように再識別や不利益を防ぐのかを整理する必要があります。個人利用者は、AIサービスやデータ活用の便利さを受け取りながらも、敏感な情報を安易に入力しないこと、利用目的や削除手続きに関心を持つことが大切です。今後の参院審議、個人情報保護委員会の規則、ガイドラインを確認しながら、保護と活用のバランスを実務に落とし込んでいきましょう。
参考情報: nippon.com: 悪質業者に「課徴金」 個人情報保護法改正案、衆院通過 / 個人情報保護委員会: 個人情報保護法等の一部を改正する法律案について / NOVAIST: 個人情報保護法改正案が衆院通過 AI・統計利用の同意例外を拡大
