
2026年6月1日、AmazonはOpenAIとの提携拡大に関する発表を更新し、OpenAIのGPT-5.5、GPT-5.4、CodexがAmazon Bedrockから利用できるようになったと説明しました。4月28日に発表されていた限定プレビューの流れが、企業の実務担当者にとってより具体的な選択肢として見え始めた形です。OpenAI側も、OpenAIモデルとCodex、OpenAIを使うAmazon Bedrock Managed AgentsがAWSに来ることを発表しており、企業がすでに使っているクラウド、セキュリティ管理、ID、調達プロセスの中でOpenAIのモデルを扱える点を強調しています。
このニュースの大きな意味は、単に「使えるAIモデルが増えた」という話にとどまりません。多くの企業では、生成AIを試したい現場の熱量と、セキュリティ、監査、契約、費用管理を担う部門の慎重さがぶつかりやすくなっています。性能の高いモデルがあっても、データをどこで処理するのか、誰がアクセスできるのか、ログをどう残すのか、請求をどう管理するのかが曖昧なままでは、本番業務に載せにくいからです。
Amazon Bedrock経由でOpenAIモデルやCodexを扱えるようになると、少なくともAWSを主要基盤として使う企業にとっては、既存のクラウド管理の延長で生成AIを検討しやすくなります。もちろん、これだけで安全性や費用対効果が自動的に保証されるわけではありません。医療、金融、法律、採用、教育、行政のように人の生活や権利に影響する領域では、AIの出力を最終判断に使う前に、根拠確認、専門家レビュー、説明責任、個人情報保護を慎重に設計する必要があります。
この記事では、2026年6月1日のAmazon公式更新とOpenAI公式発表をもとに、OpenAIがAWSで利用可能になることの実務上の意味、企業が期待できる利点、見落としやすいリスク、導入時の確認ポイントを整理します。生成AIの導入を検討している経営層、情報システム部門、開発チーム、事業部門の担当者が、過度な期待にも過度な不安にも寄らず、次の一歩を考えられる内容にします。
2026年6月1日に何が更新されたのか
Amazonの発表では、更新日として2026年6月1日が明記され、OpenAIとの提携拡大により、顧客がGPT-5.5、GPT-5.4、CodexをAmazon Bedrockから利用できるようになったと説明されています。Amazon Bedrockは、複数の基盤モデルを単一のマネージドサービスから使えるAWSの生成AI基盤です。企業はモデルごとに個別のインフラを構築するのではなく、Bedrockのモデルアクセス、オーケストレーション、ガードレール、運用管理の仕組みを通じてAIアプリケーションを作ります。
OpenAI側の発表では、OpenAIのフロンティアモデルをAWS上の既存のサービス、セキュリティ制御、IDシステム、調達プロセスと並べて使えることが示されています。さらにCodexについては、OpenAIのコーディングエージェントをAWS環境に導入できる点が打ち出されています。つまり、チャット型の文章生成だけでなく、ソフトウェア開発、コードレビュー、バグ修正、社内ツール開発のような実務にも関係する発表です。
ここで注意したいのは、発表には「限定プレビュー」や対象顧客、利用可能な地域、利用条件が絡む可能性があることです。企業がすぐ全社利用できると決めつけるのではなく、自社アカウントでの利用可否、対象リージョン、料金、データ処理条件、サポート範囲、既存契約との関係を確認する必要があります。AIニュースは華やかな表現になりやすい一方、実務では「いつ、誰が、どの条件で、どの範囲まで使えるのか」が重要です。
今回の発表を読み解くうえでの中心は、OpenAIとAWSの関係が「外部のAIサービスを別途契約して使う」だけではなく、「企業がすでに持っているAWS運用の中にOpenAIモデルを組み込む」方向へ進んでいる点です。AWSを使っている企業では、ネットワーク、IAM、監査ログ、請求、セキュリティ審査、社内承認の仕組みがすでに存在します。そこにAIモデルの選択肢が増えることで、生成AIの導入検討は、実験用ツールの導入から業務基盤の設計へ近づきます。
Amazon Bedrockとは何か
Amazon Bedrockは、AWSが提供する生成AIアプリケーション構築のためのマネージドサービスです。企業はBedrockを通じて複数のモデルを選び、プロンプト、ナレッジベース、エージェント、ガードレール、評価、監視などを組み合わせます。基盤モデルそのものを自社でホストする場合に比べて、インフラの初期構築や運用負荷を抑えやすいことが特徴です。
生成AI導入でよく起きる問題は、モデルの性能比較だけに議論が偏ることです。しかし、企業利用ではモデル単体の賢さだけでは足りません。社内データにどの範囲までアクセスさせるのか、利用者ごとに権限をどう分けるのか、出力に誤りがあったときに誰が確認するのか、費用が急増したときにどう止めるのか、監査や問い合わせに備えてログをどう保存するのか。これらをまとめて考えなければ、本番業務では使いにくくなります。
Bedrockのようなクラウド基盤を使う利点は、こうした周辺管理をクラウド運用の文脈で検討できることです。特にAWSを長く使っている企業では、IAMによる権限管理、VPCやPrivateLinkのようなネットワーク設計、CloudTrailなどのログ、請求管理、組織単位のアカウント管理に慣れています。OpenAIモデルがこの枠組みの中に入ることで、現場が新しいAIを試す際の社内説明がしやすくなる可能性があります。
ただし、Bedrockを使えばすべての課題が消えるわけではありません。モデルが出す回答の正確性、著作権やライセンス、個人情報の取り扱い、業務上の責任分界、外部連携時のデータ流出リスクは、別途設計が必要です。クラウド基盤は運用の土台を提供しますが、どの業務に使ってよいか、どの出力を人が確認するか、どの情報を入力してはいけないかは、企業側が決めるべき領域です。
GPT-5.5、GPT-5.4、Codexが意味するもの
Amazonの更新では、OpenAIのGPT-5.5とGPT-5.4が利用可能になったことが示されています。モデル名だけを見ると性能の話に見えますが、企業導入では「モデルを用途別にどう選ぶか」が重要になります。高度な推論、長い文書の整理、複雑な計画、コード生成、運用自動化、社内問い合わせ対応など、業務ごとに必要な能力は異なります。高性能モデルをすべての処理に使うと費用が膨らみやすく、軽量モデルだけでは品質が不足する場面もあります。
OpenAIのCodexがAWS上で使えることも大きな変化です。Codexは、自然言語で依頼された内容をもとにコードを読んだり、変更案を作ったり、テストや修正を支援したりする開発向けのエージェントです。これまでのAIコーディング支援は、開発者個人がエディタの補助として使う場面が目立ちました。今後は、組織のリポジトリ、権限、レビュー、CI、監査ログと接続しながら、チームの開発フローに組み込む使い方が増えていくと考えられます。
企業にとって重要なのは、AIエージェントを「便利な自動作業者」としてだけ見ないことです。コード変更は、セキュリティ、可用性、法令対応、顧客体験、コストに直結します。AIが作ったプルリクエストであっても、人間のレビュー、テスト、権限分離、監査ログ、ロールバック手順は欠かせません。特に本番環境の設定、認証認可、課金処理、個人情報を扱う処理では、AIの提案をそのまま採用しない設計が必要です。
一方で、正しく使えばCodexのような開発エージェントは、開発チームの生産性を大きく押し上げる可能性があります。既存コードの読み解き、仕様変更に伴う影響調査、単体テストの追加、ドキュメントの更新、軽微な不具合修正、レビュー観点の洗い出しなどは、人間が最終判断を持ったままAIに任せやすい領域です。これらは単純な時短だけでなく、属人化の緩和や、レビュー品質の底上げにもつながります。
企業導入で期待できる4つの利点
第一の利点は、調達と契約の整理です。多くの企業では、新しいSaaSや外部APIを使うたびに、購買、法務、セキュリティ、経理の確認が必要になります。既存のAWS利用契約やクラウド支出の管理の中でAIモデルを扱える場合、少なくとも検討の入口は整理しやすくなります。もちろん、最終的な契約条件やデータ処理条件は個別に確認する必要がありますが、社内にすでにあるクラウド統制の土台を使えることは大きな意味があります。
第二の利点は、セキュリティと権限管理の見通しです。生成AIを個人単位で導入すると、誰が何を入力し、どのデータにアクセスし、どの出力を業務に使ったのかが見えにくくなります。AWS基盤の中で管理できれば、利用者、ロール、ネットワーク、ログ、監査の設計を既存運用に寄せられます。AIの利用を禁止するだけでは現場のシャドーITを招くことがあります。管理できる場所に利用を集めることは、リスク低減の現実的な方法です。
第三の利点は、モデル選択の柔軟性です。企業のAI活用は一つのモデルだけで完結しません。高精度な推論が必要な業務、低コストで大量処理したい業務、画像や音声を扱う業務、コードを扱う業務、社内検索に近い業務では、適したモデルや構成が異なります。Bedrockのような基盤にOpenAIモデルが加わることで、既存のAWSサービスや他のモデルと比較しながら、用途ごとの構成を検討しやすくなります。
第四の利点は、開発と運用を近づけられることです。Codexのようなコーディングエージェントを、AWS上の開発環境、リポジトリ、CI/CD、監視と接続して使えるようになると、AIは単なる文章作成ツールではなく、業務システムの改善サイクルに入ってきます。問い合わせ対応の自動化、社内ツールの改修、ログ分析、障害対応の初動整理、インフラ設定のレビューなど、開発者と運用担当者の間にある反復作業を支援できる可能性があります。
見落としやすいリスクと注意点
今回の発表は前向きなニュースですが、企業がそのまま全社展開してよいという意味ではありません。まず確認すべきは、データの取り扱いです。入力した情報がどこで処理されるのか、学習に使われるのか、ログとしてどの期間保存されるのか、削除や監査の手段はあるのか。公式資料、契約条件、管理画面の設定を確認し、必要に応じて法務、セキュリティ、個人情報保護担当者がレビューするべきです。
次に、モデルの出力をどこまで信頼するかです。生成AIは自然な文章で答えるため、誤りがあっても説得力があるように見えます。社内規程、契約書、医療情報、投資判断、法律判断、採用評価、与信判断などに関わる場合、AIの出力だけで意思決定してはいけません。AIは下調べ、論点整理、草案作成には役立ちますが、最終判断は責任ある人間と専門家の確認を通す必要があります。
費用管理も重要です。高性能モデルは高度な処理に向く一方、使い方によってはコストが膨らみます。長文の社内文書を大量に投入する、エージェントが何度もツールを呼び出す、開発支援で大きなリポジトリを頻繁に読む、といった使い方では、利用量を把握しなければ予算を超えやすくなります。最初から本番業務に広げるのではなく、上限設定、利用部門別の可視化、成果指標、停止条件を決めておくべきです。
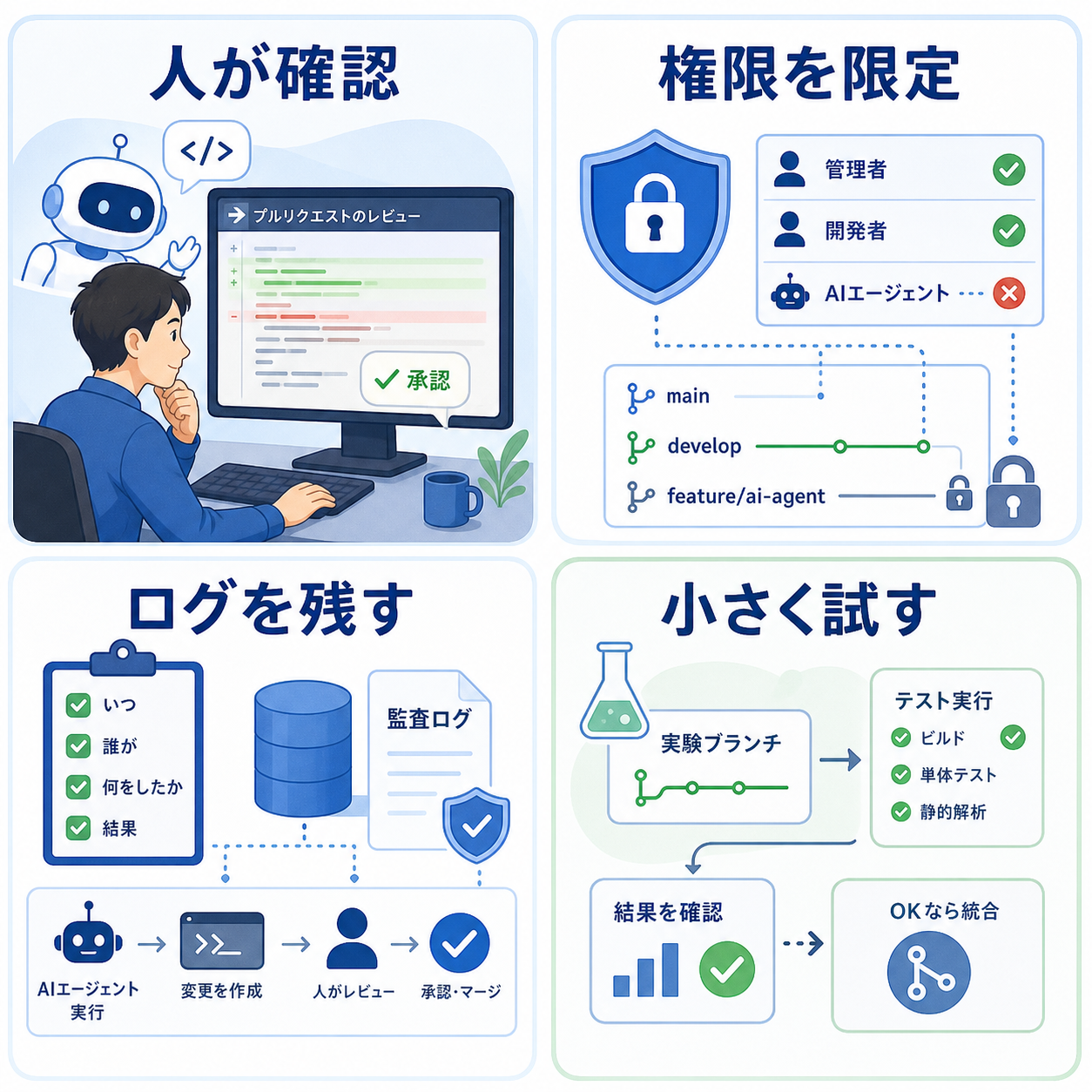
開発エージェントには別の注意点もあります。AIがコードを変更できる範囲を広げすぎると、意図しない設定変更、依存関係の更新、セキュリティ上の弱点、ライセンス不明なコードの混入が起きる可能性があります。権限は最小限にし、AIが直接本番へ反映できないようにし、必ず人間のレビューと自動テストを通す設計が必要です。AIが生成したコードであっても、責任を負うのは導入した組織です。
YMYL領域ではどう使うべきか
YMYLに近い領域では、AIの導入効果よりも先に、利用範囲と責任分界を明確にすることが大切です。医療であれば診断や治療方針の最終判断、金融であれば投資助言や与信判断、法律であれば法的助言や契約判断、採用であれば合否判断、行政であれば給付や処分の判断が人の生活に影響します。こうした領域では、AIを「判断者」ではなく「整理役」「確認補助」「文書作成支援」として位置づけるのが現実的です。
たとえば医療機関がAIを使う場合、患者向け説明文の下書き、院内マニュアル検索、研究文献の整理には使いやすい一方、個別患者の診断や投薬判断は医師の責任で確認する必要があります。金融機関では、顧客問い合わせの分類、社内規程の検索、リスク項目の洗い出しには役立ちますが、投資判断や融資判断をAIだけに任せるべきではありません。法律事務所や企業法務では、契約条項の比較や論点整理には使えても、最終的な法的評価は弁護士や担当専門家が確認する必要があります。
AWSのような管理基盤を使う場合でも、この原則は変わりません。むしろ管理基盤を使うからこそ、どの部署がどの目的で使うのか、機微情報を入力してよいのか、AI出力に免責や確認プロセスをどう付けるのかを記録しやすくなります。YMYL領域では「使えるか」よりも「どの範囲なら安全に使えるか」を先に決めることが、導入後の混乱を防ぎます。
また、読者や顧客にAI利用を説明する姿勢も重要です。AIを使った回答、要約、推奨が人間の専門的判断と同じではないことを明確にし、必要に応じて公的機関、資格者、公式文書への確認を促すべきです。便利な体験を作ることと、利用者に誤解を与えないことは両立させなければなりません。AIを使うほど、説明責任と更新管理の重要性は増します。
導入前に確認したいチェックリスト
まず、利用目的を一つに絞って始めます。「全社でAIを活用する」という大きな目標では、効果もリスクも測りにくくなります。最初は、社内FAQの下書き、問い合わせ分類、開発チームのテスト追加、営業資料の要約、ログ調査の初動整理など、業務範囲が明確で、誤りがあっても人間が確認できる領域を選ぶとよいでしょう。
次に、入力してよいデータと入力してはいけないデータを分けます。顧客の個人情報、未公開の財務情報、営業秘密、認証情報、医療情報、法的紛争に関わる情報などは、扱いを慎重に決める必要があります。社内ルールは長い規程だけでは現場に伝わりにくいため、「入力可」「条件付き」「入力不可」の具体例を短く示すことが効果的です。
三つ目に、権限とログを設計します。誰がモデルを呼び出せるのか、どのアプリから使えるのか、AIエージェントがどのリポジトリやデータベースにアクセスできるのかを制限します。ログは利用者を監視するためだけでなく、事故時の原因調査、費用分析、改善、監査対応のために必要です。ログを残すなら、保存期間、閲覧権限、個人情報の扱いも合わせて決めます。
四つ目に、評価指標を決めます。生成AIの導入は「何となく便利だった」で終わりやすい分野です。問い合わせ対応時間が何分短くなったか、レビュー指摘の漏れが減ったか、テスト追加数が増えたか、検索時間が短くなったか、誤回答率がどの程度か、利用者の満足度はどうか。定量と定性の両方を見て、継続、拡大、停止を判断するべきです。
五つ目に、モデルと費用の使い分けを決めます。すべての処理に最上位モデルを使う必要はありません。複雑な判断や重要な文章には高性能モデルを使い、分類、抽出、簡単な要約、定型処理には軽量モデルや別の構成を使う方が、費用対効果は高くなりやすいです。Bedrockのような基盤を使う場合は、モデルごとの得意分野、遅延、料金、利用上限を比較できるようにしておくと、運用後の改善がしやすくなります。
開発チームはCodexをどう位置づけるべきか
開発チームにとってCodexの価値は、単なるコード補完より広いところにあります。仕様を読んで影響範囲を洗い出す、既存のテスト傾向に合わせてテストを追加する、古いAPIの利用箇所を探す、リファクタリング案を作る、障害ログから関連コードを探す、といった作業は、開発者の時間を大きく使います。AIエージェントは、この下調べや草案作成を高速化できる可能性があります。
ただし、AIに任せる作業と任せない作業を分ける必要があります。任せやすいのは、読み取り中心の調査、テスト追加、ドキュメント更新、軽微な修正、レビュー観点の列挙です。慎重に扱うべきなのは、認証認可、課金、暗号、個人情報、データ削除、本番インフラ、法令対応に関わる変更です。これらは、AIの提案を参考にしながらも、人間の設計判断とレビューを厚くするべきです。
実務では、AIエージェント用の権限を通常の開発者権限と分けることが有効です。読み取り専用の調査、ブランチ作成、プルリクエスト作成までは許可し、本番反映や秘密情報へのアクセスは制限する。CIを必ず通し、レビュー担当者を明示し、AIが何を変更したかをログで追えるようにする。この設計があれば、AIの速度を活かしながら、変更の責任を人間のプロセスに戻せます。
また、AIが作ったコードの品質評価も必要です。動くかどうかだけでなく、保守性、セキュリティ、依存関係、ライセンス、既存設計との整合性を確認します。短期的にはAIが速く見えても、後で読みにくいコードや重複した実装が増えれば、保守コストは上がります。AIを導入するほど、設計方針、レビュー基準、テスト文化が重要になります。
中小企業や非エンジニア部門への影響
今回のニュースは大企業だけの話ではありません。AWSをすでに使っている中小企業や、クラウド基盤を外部パートナーと運用している組織にとっても、生成AI導入の選択肢が増える可能性があります。特に、社内問い合わせ、営業資料、FAQ、マニュアル検索、請求関連の確認、在庫や業務ログの要約などは、専門のAIチームがなくても効果を試しやすい分野です。
ただし、中小企業ほど「便利だから使う」が先行しやすく、ルール作りが後回しになりがちです。個人情報や取引先情報をAIに入力してよいか、外部委託先がAIを使う場合の責任はどうなるか、社内資料の著作権や機密性をどう守るかは、規模に関係なく確認が必要です。むしろ担当者が少ない組織ほど、最初に簡単な利用ルールを作り、使う範囲を限定することが重要です。
非エンジニア部門では、AIを「自分の仕事を奪うもの」と見るより、「面倒な下準備を短縮するもの」として導入する方が受け入れられやすいでしょう。会議メモの整理、長い資料の要約、問い合わせメールの下書き、手順書のたたき台、表の分類、アイデア出しなどは、最終確認を人間が行う前提なら取り入れやすい使い方です。重要なのは、AIの出力を完成品ではなく下書きとして扱う文化です。
サイト運営者やブロガーが押さえたい視点
AIニュースを扱うサイト運営者やブロガーにとって、今回の発表は「OpenAIがAWSに来た」という見出しだけでは伝えきれません。読者が知りたいのは、自分の仕事や会社に何が関係するのか、すぐ使えるのか、どこに注意すべきかです。記事では、公式発表の日付、利用条件、限定プレビューの有無、対象サービス、企業導入での確認点を明確にすると、読者が判断しやすくなります。
また、モデル名やサービス名を並べるだけでは、一般読者には意味が伝わりにくいです。Amazon Bedrockは「複数のAIモデルをAWSの管理基盤から使うためのサービス」、Codexは「コードを読んで変更案を作る開発向けAIエージェント」のように、具体的な利用場面へ翻訳することが大切です。難しいニュースほど、専門用語を減らすのではなく、専門用語の役割を短く説明する必要があります。
YMYLに近いテーマを扱う場合は、断定的な助言を避けることも重要です。AI導入、セキュリティ、費用、法律、医療、金融に関わる内容では、個別事情によって結論が変わります。記事では、一般的な整理であること、公式資料や専門家への確認が必要なこと、最新の提供条件を確認すべきことを明記すると、読者の誤解を減らせます。
画像のalt文も軽視できません。今回のような記事では、単に「AI画像」とするのではなく、「OpenAIモデルがAWSで使える意味を説明する4コマ漫画」「Amazon BedrockでAI導入を評価から本番まで進める流れ」のように、画像が何を説明しているかを短く具体的に書くと、アクセシビリティと記事理解の両方に役立ちます。
まとめ:企業AIは「試す」から「管理して使う」へ進む
OpenAIのGPT-5.5、GPT-5.4、CodexがAmazon Bedrockから利用できるようになったという2026年6月1日の更新は、生成AIの企業導入が次の段階に入っていることを示しています。注目点は、最新モデルの性能だけではありません。既存のAWS環境、セキュリティ制御、ID、調達、請求、ログ、開発フローと結びつけてAIを扱える可能性が広がることです。
企業にとっては、AI導入の入口が広がる一方で、責任ある運用の重要性も増します。データの扱い、権限、費用、監査ログ、出力確認、YMYL領域での人間の最終判断、開発エージェントのレビュー体制を決めないまま進めると、便利さがリスクに変わります。今回のニュースは「AIをすぐ全面導入すべき」という合図ではなく、「管理できる形で試し、成果とリスクを測る準備が整いつつある」という合図として読むのが現実的です。
最初の一歩は、小さな業務を選び、入力データを限定し、利用者と権限を決め、成果指標と停止条件を置くことです。問い合わせ分類、社内文書検索、開発テストの追加、ログ要約、営業資料の下書きなど、効果を測りやすく人間が確認できる業務から始めると、過度な期待に流されにくくなります。
OpenAIとAWSの提携拡大は、生成AIを特別な実験環境から日常のクラウド運用へ近づける動きです。これから重要になるのは、どのモデルが最も話題かではなく、自社の業務、責任、データ、予算に合う形でAIを使えるかです。AIの性能競争が進むほど、導入する側には冷静な設計力が求められます。

