
# OpenAIとDellのCodex提携で何が変わるのか 企業AIエージェントは「クラウドで試す」から「社内データの近くで動かす」段階へ

2026年5月18日、OpenAIはDell Technologiesとの協業を発表しました。テーマは、OpenAIのAIコーディングエージェントであるCodexを、企業のハイブリッド環境やオンプレミス環境に近づけることです。OpenAIの発表によれば、Codexはすでに週あたり400万人以上の開発者に使われ、コードレビュー、テストカバレッジ、インシデント対応、大規模リポジトリの理解など、ソフトウェア開発ライフサイクルの広い範囲で使われています。さらにOpenAIは、Codexの用途がコーディングだけでなく、ツールを横断した文脈収集、レポート作成、製品フィードバックの整理、営業リードの評価、フォローアップ文面の作成、業務システム間の調整にも広がり始めていると説明しています。
今回のニュースで重要なのは、「AIが賢くなった」という単純な話ではありません。むしろ、AIエージェントを本番業務に使ううえで避けられない、データの所在、権限管理、監査、既存システムとの接続、運用責任という現実的な課題に焦点が移っている点です。企業がAIエージェントを試験導入する段階では、クラウド上のチャット画面や開発者向けツールだけでも十分に価値を確認できます。しかし、社内のコードベース、設計書、顧客対応履歴、業務システム、運用ナレッジに触れる段階になると、AIをどこで動かすのか、どのデータにアクセスさせるのか、出力や操作履歴をどう管理するのかが導入可否を左右します。
本記事では、2026年5月18日のOpenAIとDell Technologiesの発表をもとに、Codexと企業AIエージェントの現在地を整理します。あわせて、日本企業がこの動きをどう受け止めるべきか、導入時に確認したい論点もまとめます。なお、本記事は公開情報にもとづく一般的な解説であり、特定の製品導入、投資判断、法務判断、セキュリティ設計を推奨するものではありません。重要な意思決定では、最新の公式情報、契約条件、社内規程、専門家の助言を必ず確認してください。
OpenAIとDellの提携内容を短く整理する
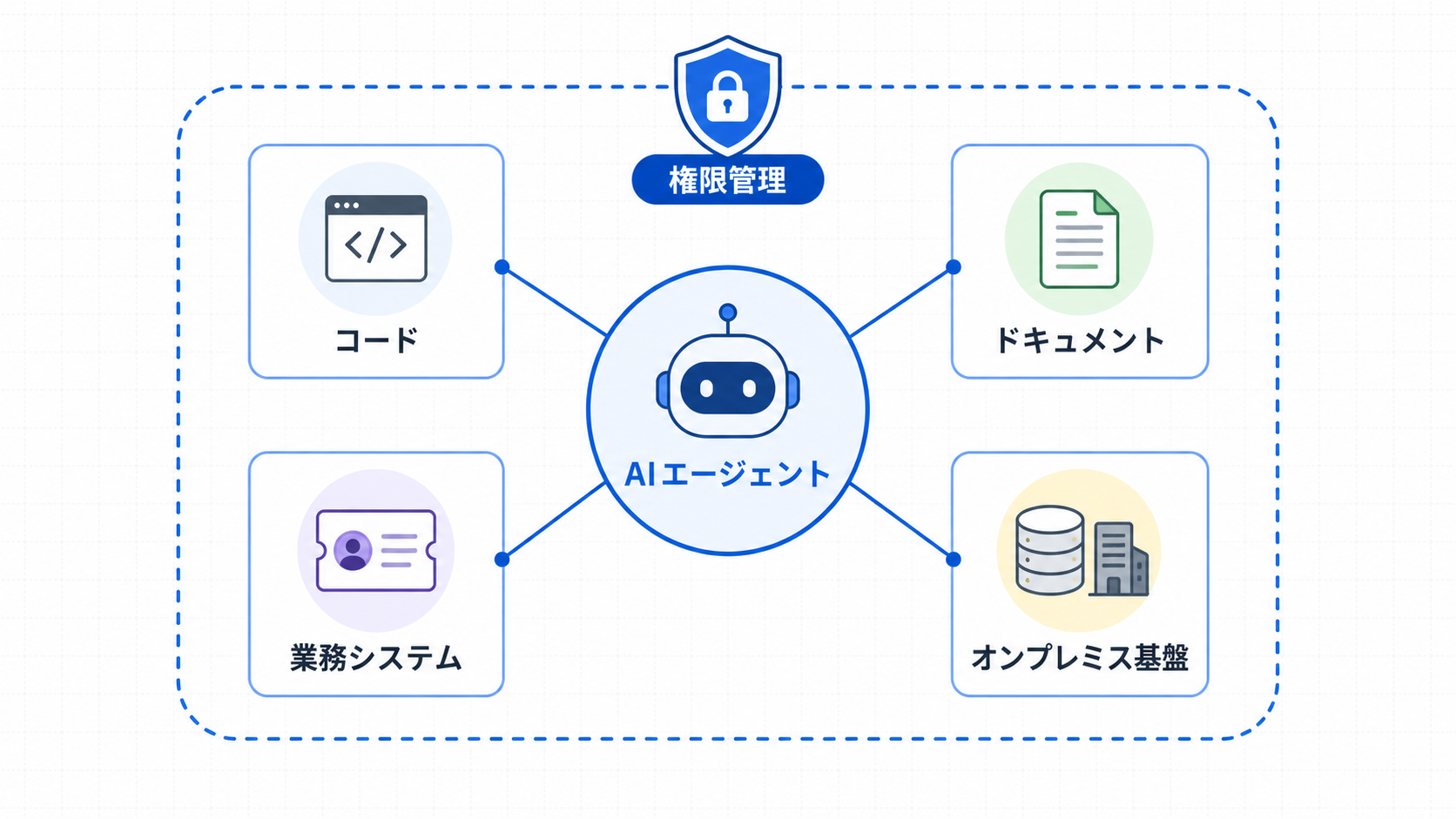
OpenAIの発表の中心は、Codexを企業の重要なデータ、システム、ワークフローがすでに存在する場所で使いやすくすることです。具体的には、Dell AI Data Platformとの接続が挙げられています。このプラットフォームは、企業がオンプレミスでデータを保存、整理、ガバナンスするために使う基盤と説明されています。OpenAIは、Codexがこうした企業データ基盤に近づくことで、コードベース、ドキュメント、業務システム、運用知識、チームのワークフローといった内部文脈を取り込みやすくなるとしています。
さらに、Dell AI Factoryとの接続も検討対象に入っています。Dell AI Factoryは、企業がAIワークロードを動かすための基盤として位置づけられており、OpenAIはCodex、ChatGPT Enterprise、APIベースのソリューションが、データ準備、システム・オブ・レコードの管理、テスト実行、ハイブリッドまたはオンプレミスのDellインフラと統合されたAIアプリケーションのデプロイに関わる可能性を示しています。
Dell側の発表も、より広い文脈で同じ方向を示しています。Dell Technologiesは、Dell AI Factory with NVIDIAの拡張を発表し、AIを実験から成果へ移すためには、企業が制御できるインフラ、信頼できるデータ、セキュリティ、ガバナンス、コスト効率が重要だと説明しています。その中で、OpenAIとの協業は、Codexをオンプレミスで統治された企業データに近づける取り組みとして位置づけられています。
この2社の発表を合わせると、狙いは明確です。AIエージェントを「外部の便利なツール」として使うだけでなく、企業の既存IT環境、データ基盤、運用ルールの中に組み込むことです。これはクラウド利用を否定する動きではありません。むしろ、クラウド、オンプレミス、エッジ、開発者端末、業務アプリケーションが混在する現実の企業環境に合わせて、AIエージェントの配置と接続方法を増やす動きと見るべきです。
なぜ「社内データの近くで動かす」ことが重要なのか
AIエージェントは、単独で賢いだけでは業務に深く入り込めません。業務で価値を出すには、社内固有の文脈を理解する必要があります。たとえば、あるコードの変更が安全かどうかを判断するには、リポジトリ全体の構造、過去の障害、テスト方針、リリース手順、チームのコーディング規約、利用中のクラウドサービス、顧客ごとの例外対応まで関係します。一般的なプログラミング知識だけでは、実務上の判断には届きません。
同じことは、営業、カスタマーサポート、経理、人事、法務、調達にも当てはまります。AIが文書を要約できるとしても、どの資料を参照してよいのか、最新版はどれか、社外秘の範囲はどこか、承認を得るべき相手は誰か、顧客ごとの契約条件は何かを理解できなければ、本番業務には使いにくいままです。AIエージェントの価値は、モデル単体の能力だけでなく、正しい内部文脈に安全に接続できるかどうかで決まります。
ここで問題になるのが、データの移動です。多くの企業では、機密性の高いコード、設計書、顧客情報、業務ログ、財務データ、個人情報を外部環境へ自由に持ち出せません。規制産業でなくても、情報管理規程、取引先との契約、知的財産の保護、監査対応の観点から、データの保存場所と処理場所は慎重に扱われます。そのため、AIエージェントを導入したくても、「社内データを外に出せない」「どこまで学習や推論に使われるのか説明しにくい」「ログや権限の管理が既存ルールと合わない」という壁が生まれます。
今回のOpenAIとDellの協業は、この壁に対するひとつの回答です。AIエージェントを企業データの近くに置く、または企業データ基盤と統治された形で接続することで、文脈の深さと管理可能性を両立しようとしています。もちろん、発表された協業だけで全ての企業課題が解決するわけではありません。しかし、AIエージェントの競争軸が「モデルの性能」だけでなく、「企業データと安全に接続する設計」に広がっていることは読み取れます。
Codexはコーディング支援から業務エージェントへ広がっている
Codexという名前から、開発者向けのコード生成ツールを想像する人は多いでしょう。実際、Codexの中核はソフトウェア開発支援です。コードの理解、変更提案、テスト作成、リファクタリング、障害調査、レビュー支援などは、開発現場で分かりやすい価値を出しやすい領域です。ソフトウェア開発は、仕様、コード、ログ、テスト、チケット、ドキュメントがテキスト中心で残りやすく、AIエージェントが参照しやすい情報も多いからです。
ただし、OpenAIはCodexがコーディングを超えて広がっていると説明しています。チームが複数ツールから情報を集め、何が重要かを判断し、ブリーフ、計画、チェックリスト、下書き、フォローアップを作成し、その後のアクションにつなげる。こうした用途は、開発者以外の部門にも関係します。つまりCodexは、単なるコード生成ツールというより、仕事の文脈を読み取り、作業を進めるエージェント基盤として位置づけられつつあります。
ここで企業側が注意したいのは、用途が広がるほどリスクも広がることです。コードレビュー支援であれば、対象は主にリポジトリや開発環境です。しかし、営業フォローアップ、顧客対応、業務システム操作、レポート作成に広がると、顧客情報、契約情報、売上見通し、個人情報、社内意思決定に触れる可能性があります。便利だからといって接続先を増やすだけでは、権限過多、誤送信、誤った自動操作、監査困難といった問題が起きやすくなります。
AIエージェントの導入で大切なのは、できることを増やす順番です。最初から全社の業務システムに接続するのではなく、影響範囲が限定されたリポジトリ、社内文書、ナレッジベース、チケット管理などから始め、出力の品質、操作ログ、アクセス制御、ユーザー体験を確認する。次に、人間の承認を挟むワークフローへ進み、最後に限定された自動実行へ移す。この段階設計がないまま導入すると、成功事例より先に事故対応が増える可能性があります。
ハイブリッドとオンプレミスが再び注目される理由
生成AIの普及初期には、クラウドサービスとしての使いやすさが導入を大きく後押ししました。ブラウザからすぐ使える、APIで試せる、インフラ調達が不要、モデル更新が速いという利点は今も大きいものです。一方で、企業の本番活用が進むにつれて、全てをクラウドだけで処理する設計が合わない場面も見えてきました。
理由のひとつは、データ主権とコンプライアンスです。金融、医療、公共、製造、防衛、重要インフラなどでは、データの保管場所や処理場所が厳しく問われます。海外クラウドの利用そのものが不可という意味ではありませんが、どの国や地域で処理されるのか、どの事業者がアクセスできるのか、監査証跡をどう出すのか、障害時にどう説明するのかは重要です。オンプレミスやハイブリッド構成は、こうした要件に対応する選択肢になります。
もうひとつは、既存システムとの距離です。企業の基幹システム、データウェアハウス、ファイルサーバー、コード管理基盤、ID管理基盤は、長年の運用の中で複雑に絡み合っています。AIエージェントを外部から接続するだけでは、ネットワーク、認証、権限、遅延、ログ取得、変更管理の調整が難しくなる場合があります。データやワークロードの近くでAIを動かせれば、既存の監視、認証、監査、運用フローを活用しやすくなります。
コストと性能も無視できません。AIエージェントが本番業務に組み込まれると、利用量は実験段階とは比較にならないほど増える可能性があります。全ての推論やデータ処理を外部APIで行うのか、一部を社内基盤で処理するのか、どのモデルをどの用途に使うのかによって、コスト構造は変わります。オンプレミスは初期投資や運用負荷があるため万能ではありませんが、データ量、利用頻度、遅延要件、既存インフラ、人材体制によっては現実的な選択肢になります。
今回の発表は、クラウド対オンプレミスという二項対立ではなく、AIを業務に合わせて配置する時代への移行を示しています。機密性が高く、低遅延で、既存データ基盤に近い処理は社内環境へ。広く使う汎用的な機能や最新モデルの試用はクラウドへ。部門ごとの開発や検証はデスクサイドやワークステーションへ。こうした組み合わせを設計できる企業ほど、AIエージェントの活用範囲を広げやすくなります。
企業AI導入の成否はガバナンスで決まる
AIエージェントを本番業務に入れるとき、性能評価だけでは不十分です。むしろ最初に確認すべきなのは、誰が、何に、どの条件でアクセスできるのかです。人間の社員であれば、部署、役職、プロジェクト、雇用形態、委託契約に応じて権限を分けます。AIエージェントにも同じ発想が必要です。全社のデータを横断できる万能エージェントを作るのではなく、用途ごとに最小権限を設定し、不要なデータには触れさせない設計が基本になります。
監査ログも重要です。AIエージェントがどの資料を参照し、どのコードを読み、どの操作を提案し、誰が承認し、どの結果になったのかを追跡できなければ、問題発生時の原因調査が難しくなります。とくに、コードの自動変更、顧客向け文面の生成、業務システムへの入力、承認フローの更新などでは、ログが残っていることが信頼の前提です。便利さを優先してログを軽視すると、あとから導入範囲を広げにくくなります。
評価の仕組みも欠かせません。AIエージェントは、もっともらしい回答を出すことがありますが、常に正しいとは限りません。開発支援であれば、テストが通るか、脆弱性を増やしていないか、既存仕様を壊していないかを確認する必要があります。業務文書であれば、参照元の正確性、日付、数字、固有名詞、社内ルールとの整合性を確認しなければなりません。評価指標を決めずに導入すると、便利に見えるが品質が安定しない状態になりがちです。
運用体制も現実的に考える必要があります。AIエージェントの出力に問題があったとき、利用部門、IT部門、セキュリティ部門、法務部門、ベンダーのどこが対応するのか。モデル更新やツール連携変更があったとき、誰が再評価するのか。利用者が誤った指示を出したとき、どのように検知し、教育するのか。これらを決めないまま「AIで業務効率化」とだけ進めると、導入後の負担が現場に集中します。

日本企業にとっての示唆
日本企業にとって、今回のニュースは遠い海外テック企業の話ではありません。日本でも、生成AIの社内利用はすでに広がっています。文章作成、議事録、翻訳、問い合わせ対応、社内検索、プログラミング支援など、利用場面は増えています。一方で、本番業務への組み込みでは、情報管理、個人情報保護、委託先管理、監査、労務、説明責任が壁になりやすいのも事実です。
とくに日本企業では、現場ごとにExcel、メール、チャット、ファイルサーバー、独自システムが混在し、暗黙知が多く残っています。AIエージェントが本当に役立つには、こうした散らばった文脈にアクセスする必要があります。しかし、アクセスできる範囲を広げすぎると、機密情報の取り扱いが難しくなります。ここで重要になるのが、社内データを整備し、アクセス権限を見直し、業務プロセスを棚卸しすることです。AI導入は、モデル選定だけでなく、情報整理のプロジェクトでもあります。
また、開発部門にとっては、CodexのようなAIコーディングエージェントの導入が、内製化やレガシー刷新に影響する可能性があります。日本企業では、基幹システムの保守、古いコードの理解、テスト不足、ドキュメント不足、属人化が課題になりがちです。AIエージェントが大規模リポジトリを読み、変更候補を作り、テストを提案し、影響範囲を説明できるなら、保守開発の生産性を上げる可能性があります。ただし、AIが出したコードをそのまま本番投入するのではなく、レビュー、テスト、セキュリティチェック、変更管理を組み合わせることが前提です。
非エンジニア部門にも影響はあります。社内規程の検索、契約書の要点整理、顧客対応履歴の要約、FAQの更新、商品企画の調査、経営会議資料の下書きなど、AIエージェントが支援できる作業は多いでしょう。ただし、これらの作業は正確性と説明責任が求められます。AIが参照した資料、生成した文章、変更した箇所が追跡できないと、業務で安心して使うことはできません。日本企業がAIを広げるには、現場の便利さと統制の両方を満たす設計が必要です。
導入を検討する企業が確認したい7つの論点
1つ目は、利用目的の明確化です。AIエージェントを何に使うのかを曖昧にしたまま導入すると、評価もリスク管理も難しくなります。コードレビュー支援なのか、テスト作成なのか、障害調査なのか、社内文書検索なのか、営業支援なのか。目的ごとに必要なデータ、許容できるリスク、評価方法は変わります。
2つ目は、接続するデータの分類です。公開情報、社内限定情報、機密情報、個人情報、顧客情報、契約情報、ソースコード、運用ログを同じ扱いにしてはいけません。AIエージェントに接続する前に、データ分類とアクセス権限を整理する必要があります。データの棚卸しができていない場合、AI導入はその問題を見えやすくします。
3つ目は、権限管理です。AIエージェントの権限は、利用者の権限、用途、承認状態に応じて制御すべきです。人間が見られない資料をAIが見られる設計は避ける必要があります。また、参照だけを許すのか、変更提案まで許すのか、実際の書き込みや実行まで許すのかを段階的に分けることが重要です。
4つ目は、監査ログと説明可能性です。AIエージェントが参照した情報、生成した出力、実行した操作、承認者、時刻、結果を記録できるかを確認します。問題が起きたときに「AIがやりました」では説明になりません。誰がどの条件で使い、どの判断が行われたのかを追えることが、社内外への説明責任につながります。
5つ目は、品質評価です。開発用途なら、テスト通過率、脆弱性検出、コードレビュー品質、既存仕様との整合性を評価します。文書用途なら、事実関係、引用元、日付、数値、固有名詞、社内ルールとの整合性を確認します。評価データを用意せずに本番運用へ進むと、問題が起きるまで品質の弱点に気づけません。
6つ目は、運用と教育です。AIエージェントは導入して終わりではありません。利用者教育、プロンプトや手順の整備、失敗事例の共有、モデル更新時の再評価、インシデント対応、利用状況のレビューが必要です。特に、AIの出力を過信しない文化づくりは重要です。AIは判断を支援する道具であり、責任を置き換える存在ではありません。
7つ目は、ベンダーと契約条件の確認です。データの保存、学習利用の有無、処理地域、サブプロセッサ、ログ保持、監査対応、障害時の通知、サービス終了時のデータ削除、知的財産の扱いなどを確認します。今回のように大手同士の協業が発表されても、自社の契約条件や利用形態で何が保証されるかは別問題です。導入前に公式ドキュメントと契約書を確認する必要があります。
AIエージェント活用で避けたい誤解
最初の誤解は、「オンプレミスなら安全」という考え方です。社内環境で動かすことは、データ管理や監査の面で利点を持つ場合があります。しかし、オンプレミスであっても、権限設定が甘ければ情報漏えいは起こります。パッチ管理が遅れれば脆弱性も残ります。ログが不十分なら説明責任も果たせません。場所だけで安全性は決まりません。
次の誤解は、「AIエージェントを入れれば業務が自動的に改善する」という考え方です。AIエージェントは、業務プロセスが整理されているほど力を発揮します。逆に、データが散らばり、承認フローが曖昧で、責任分界が不明な業務にAIを入れると、混乱が増えることがあります。AI導入は、業務改善を代替するものではなく、業務改善を加速するための道具です。
もうひとつの誤解は、「開発者向けツールだから非エンジニアには関係ない」という見方です。Codexのようなエージェントがコードから業務文脈へ広がるなら、IT部門だけでなく、事業部門、管理部門、法務、セキュリティ、人事にも関係します。AIが業務システムや社内文書に接続するほど、組織全体のルール設計が必要になります。
最後の誤解は、「人間の確認を入れれば十分」という考え方です。人間の承認は重要ですが、承認者が十分な情報を持たず、忙しい中で機械的に承認するだけなら、実質的な統制にはなりません。AIエージェントの提案には、根拠、差分、影響範囲、リスク、代替案が分かる形で提示される必要があります。人間の確認を機能させるには、確認しやすい設計が必要です。
競争軸は「モデル性能」から「企業で使える形」へ
AI業界では、モデルの性能、価格、速度、コンテキスト長、マルチモーダル能力が注目されがちです。もちろん、これらは今後も重要です。しかし、企業の本番活用では、それだけでは不十分です。社内データに安全に接続できるか。既存のID管理、監査、運用、セキュリティ基盤と連携できるか。導入後にサポートを受けられるか。障害時に説明できるか。現場のワークフローに自然に組み込めるか。こうした点が実用性を左右します。
OpenAIは4月にもAWSとの協業を発表し、OpenAIモデル、Codex、Managed AgentsをAWS環境で使う方向性を示していました。今回のDellとの発表は、その流れをさらにオンプレミスやハイブリッド環境へ広げるものと見ることができます。つまり、OpenAIはモデルやアプリを提供するだけでなく、企業がすでに使っているインフラや購買、セキュリティ、運用の枠組みに入り込む戦略を進めています。
Dellにとっても、AIエージェントの広がりはインフラ需要を生む重要なテーマです。AIを本番業務で使うには、GPUやストレージだけでなく、データ整理、ネットワーク、冷却、運用管理、セキュリティ、サポートが必要です。Dell AI FactoryやDell AI Data Platformは、こうした企業向けの基盤をまとめて提供する文脈で語られています。OpenAIとの協業は、そこに強力なエージェント活用シナリオを加えるものです。
この競争軸の変化は、他のAI企業やクラウド企業にも波及するでしょう。企業顧客は、単に最先端モデルを使いたいだけではありません。社内ルールに合う形で使いたい。コストを予測したい。監査に耐えたい。既存システムとつなぎたい。利用者に教育しやすい形で展開したい。今後のAI市場では、こうした現実的な要求に応えられる企業が優位に立ちやすくなります。
読者が今できる準備
このニュースを読んで、すぐに特定の製品を導入する必要はありません。むしろ、まず取り組むべきことは、自社のAI利用状況とデータ管理の現状を確認することです。どの部門がどのAIツールを使っているのか。どのデータを入力しているのか。社内規程は整っているのか。機密情報や個人情報の扱いは明確か。ログや承認の仕組みはあるのか。こうした足元の確認が、次の導入判断の土台になります。
開発組織であれば、AIコーディングエージェントを使う対象リポジトリを限定し、テストとレビューの基準を整えることから始められます。重要な本番コードではなく、ドキュメント更新、テスト追加、静的解析の補助、影響範囲調査など、リスクを抑えやすい用途から評価するのが現実的です。評価結果は、速度だけでなく、品質、レビュー負荷、手戻り、セキュリティ、開発者体験で見るべきです。
事業部門であれば、AIに任せたい業務をいきなり自動化するのではなく、情報収集、要約、下書き、チェックリスト作成など、人間が確認しやすい支援業務から始めるのがよいでしょう。AIが生成した内容を誰が確認するのか、どの資料を根拠にしたのか、顧客向けに出す前にどの承認が必要なのかを決めておくことが重要です。
経営層やIT責任者にとっては、AIを「個人の便利ツール」として放置する段階から、「企業の業務基盤」として設計する段階へ移るタイミングです。AI利用を止めるか進めるかではなく、どの条件なら安全に進められるかを決める必要があります。今回のOpenAIとDellの発表は、その条件づくりにおいて、ハイブリッド、オンプレミス、ガバナンス、データ基盤が中心テーマになることを示しています。
まとめ 企業AIエージェントは本番運用の入口に立った
2026年5月18日のOpenAIとDell Technologiesの協業発表は、AIエージェント市場の成熟を示すニュースです。Codexは、コーディング支援から企業内の知識作業や業務ワークフローへ広がりつつあります。その一方で、本番業務に入るほど、データの所在、権限、監査、評価、運用、契約条件が重要になります。
今回の提携が示しているのは、AIエージェントを企業データの近くで、統治された形で使う方向性です。これは、AIの価値がモデル単体では完結しないことを意味します。社内データ、既存システム、セキュリティ基盤、運用プロセス、人間の承認と組み合わさって初めて、AIエージェントは本番業務で使えるものになります。
日本企業にとっても、重要なのは流行に乗ることではありません。自社のデータを整理し、アクセス権限を見直し、評価と監査の仕組みを作り、現場が安心して使える範囲から始めることです。AIエージェントは、業務を自動化する魔法の箱ではなく、仕事の文脈に深く入り込む道具です。だからこそ、便利さと統制を同時に設計できる企業が、次の段階で大きな差をつけることになります。
参考資料
- OpenAI: OpenAI and Dell Technologies partner to bring Codex to hybrid and on-premises enterprise environments
- Dell Technologies: Dell Technologies Closes the Gap Between AI Ambition and AI Outcomes
- OpenAI: Scaling Codex to enterprises worldwide
- OpenAI: OpenAI models, Codex, and Managed Agents come to AWS
- OpenAI Help Center: ChatGPT Enterprise & Edu Release Notes

